2025年度 三菱電機ソフトウエア技術レポート
連合学習の地震動予測モデル改善への適用
1.まえがき
地震の規模、震源の位置や深さ、地盤の性質などをもとにある地点での揺れの強さを予測する地震動予測モデルは、緊急地震速報 [1]や地震リスク評価 [2]において幅広く活用されている。予測モデルには様々な種類があるが、特に即時性が求められる場面では計算速度や予測の説明性の観点から経験的な回帰式による距離減衰式 [3]が用いられている。このような予測モデルは公的な研究機関等が公開する観測データ(以下、パブリックデータ)を利用して構築・改善されることが多い。
一方、民間の組織では、独自に保有する観測網による地震観測を行うことがあるが、観測点を設置している地域や期間が限定的であることなどから、これらの観測データ(以下、プライベートデータ)はパブリックデータとは異なる性質を持つデータセットとなることがある。このようなデータには、パブリックデータで学習された既存の距離減衰式では十分な予測精度が得られず、またプライベートデータのみではデータ数が少ないために予測モデルの構築に十分な学習を行うことが難しいという問題が生じることがある。また、研究機関等においても、各事業者が持つ高密度な観測データは距離減衰式の精度および汎化性の向上のために重要視されており、両者のデータを統合した予測モデルの構築は不可欠である。しかし、このような独自観測データは各事業者における機密情報となるため、外部への提供が行えない状況にある。
各事業者の持つ個別の観測データを互いに秘匿した状態で予測モデルを構築可能な手法として、秘密計算や連合学習(Federated Learning、FL) [4]が挙げられる。秘密計算はデータを暗号化した状態で演算を行う技術であり、秘密分散 [5]を代表とするセキュアマルチパーティ計算(Secure Multi-Party Computation、SMPC)および準同型暗号(Homomorphic Encryption、HE) [6]などの手法がある。秘密分散はデータを乱数の断片に分解した上で別々の環境で保持・計算を行う手法であり、断片だけでは元の情報を復元できないため高いセキュリティ効果を持つ。また、準同型暗号は暗号化状態で四則演算を行う手法であり、計算時に復号を行わないためデータ漏洩リスクが極めて低い。しかしこれらの手法は数値を暗号化したまま演算を行うため、計算コストが高く計算誤差が大きくなるという課題がある。一方、連合学習は学習に参加する各クライアントがローカル環境でモデルを更新した後、モデルの更新情報のみを集約してモデル改善を行うため、秘密計算と比較して計算コストが低く演算の誤差も生じない。
本研究では、連合学習を用いて複数クライアントの観測データをお互いに秘匿した状態で司・翠川 [7]による距離減衰式の学習を行い、得られた予測モデルの評価を行った。観測データとして、防災科学技術研究所(以下、防災科研)が公開している強震動データフラットファイル [8]を用いた。一般的な傾向と比べて、データの分布に偏りのあるデータセットをフラットファイルから抽出し、模擬的なクライアントデータとして使用することとした。なお、連合学習では学習に参加するクライアント間でデータ分布が独立同分布(Independent Identically Distributed、IID)でない場合に中央集約型学習(全データを中央サーバに集約して行う学習)によるモデルと連合学習によるモデルが乖離する問題がある [9]。そのため、全クライアント間で少量のデータを共有することでデータ分布の偏りを軽減する手法 [10]を取り入れ、その効果を検証した。
2.基礎技術
2.1連合学習
連合学習はデータを一箇所に集めずに、個々の環境で学習したモデルの情報を集約することで、各組織のデータの秘匿性を保ちながらもそれらのデータの性質を反映したモデル構築を実現する手法である。連合学習は分析対象となるデータセットの特性に応じて、Horizontal(水平)型 [4] とVertical(垂直)型 [11]の二種類に分類される。Horizontal 型は、異なる識別子を持ちながら同一の特徴量を有する複数のデータセットを用いて学習を行う場合に適用される。一方、Vertical 型は同じ識別子に対して異なる特徴量を持つ複数のデータセットを活用する場合に用いられる。今回は、異なる地点で観測された同一の特徴量を有する観測データを対象とするため、Horizontal 型連合学習を採用する。以下では特に断りのない限り「連合学習」という表現は Horizontal型を指すものとする。連合学習のプロセスは以下のように進行する。
- ①集約者(中央サーバ)が初期化したグローバルモデルを各クライアントに送信する。
- ②各クライアントがローカルデータを用いてモデルを更新し、その結果を集約者に送信する。
- ③集約者は各デバイスから得た更新情報を集約してグローバルモデルを更新し、各クライアントに再配布する。
なお、通常②~③ の手続きは複数回繰り返される。
連合学習において、ローカルモデルを集約しグローバルモデルを更新するためのアルゴリズムはこれまでに多く提案されている [9]。本研究では、最も基本的なモデル集約アルゴリズムであるFedAvg [12]を用いた。FedAvg では各クライアントが学習したローカルモデルのパラメータを、更新に使用したデータ量に応じて重み付けし、その加重平均をグローバルモデルのパラメータとして採用する。このとき各クライアントの貢献度は、そのデータサンプル数に比例する。FedAvg におけるグローバルモデルの更新は次式で表される。
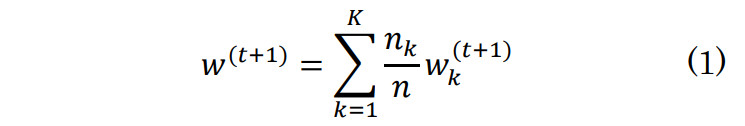
ここで、Kは全クライアント数、
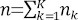 は全クライアントのデータセットの総サンプル数、
は全クライアントのデータセットの総サンプル数、
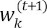 はクライアント𝑘のローカルモデルの重みであり、
はクライアント𝑘のローカルモデルの重みであり、
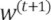 は更新後のグローバルモデルの重みである。
は更新後のグローバルモデルの重みである。
2.2距離減衰式
距離減衰式は、地震観測データを回帰することにより、地震の規模や震源からの距離と地震動の強さの関係を評価した経験的なモデルである。地震動の強さを支配する要因として、震源特性や伝播特性、地盤特性を考慮して定義される場合が多く、複数の距離減衰式がこれまでに提案されている [7] [13]。本研究では司・翠川 [7]の距離減衰式を採用した。司・翠川の式を用いた震度の計算方法は以下の通りである。
まず、距離減衰式を用いて平均S 波速度600m/sの工学基盤上における最大速度(Peak Ground Velocity)の常用対数logPGVb600を計算する。
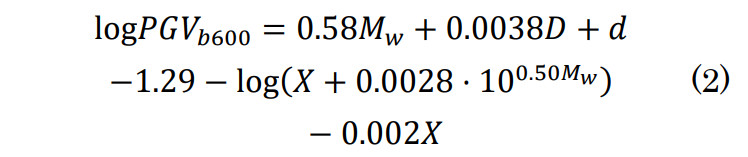
このとき、Mwはモーメントマグニチュード、Dは震源深さ、dは地震タイプ別の係数(地殻内地震: 0、プレート間地震: -0.02、プレート内地震: 0.12)、Xは断層最短距離である。
次に、logPGVb600に地盤増幅率ARVを乗じて地表での最大速度を推定する。地盤増幅率とは工学的基盤上の地震動が地表面または別の工学的基盤上において増幅される倍率である。増幅率ARVの計算には式(3)に示す松岡・翠川 [14]の表層地盤の速度増幅度算定式を用いた。
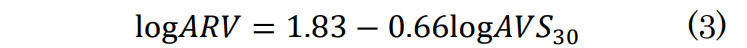
ここで、AVS30は地表から深さ30mまでの平均S波速度である。得られたARVを用いて、地表での最大速度PGVsを式(4)により求める。
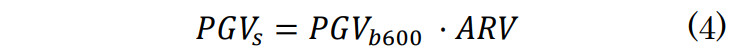
最後に、算出された地表での最大速度PGVsを用いて計測震度yを計算する。
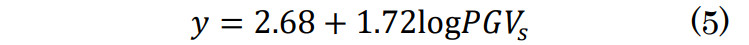
以下では、特に断りのない限り「震度」は計測震度を指すものとする。
2.3強震動データフラットファイル
強震動データフラットファイル [8] [15]は、日本国内で観測された地震の強震動観測記録を統一的に扱うための共通基盤として構築されたTSV形式のデータファイルであり、防災科研によって公開されている。従来強震動観測記録は提供元機関や観測網ごとに提供されている指標の種類や計算方法が異なることによる情報の欠落や非一貫性があった。この問題の解決のため共通のデータ処理手順、データ形式を定義してデータの統合を行ったものが本データファイルである。提供されているファイルでは震源位置やモーメントマグニチュードを含む震源情報、最大加速度や震度・加速度応答スペクトルを含む強震動指標、観測点位置や地盤情報を含む観測点情報に分けて整理されている。
3.地震動予測モデルへの連合学習の適用手法
3.1課題
独自に地震観測を実施する事業者単一の観測データ(以下、秘匿データ)では、学習に必要なデータ規模の確保が困難な場合がある。そのため、秘匿データを学習データとして保有するクライアントに加え、強震動データフラットファイル [8]の公開観測データ(以下、公開データ)を学習データとして保有するクライアントが参加する連合学習システムを設計する。
しかし、この方法では秘匿データを保有するクライアントと公開データを保有するクライアント間で学習データが非IIDとなる可能性が高い。そこで、本システムでは、Zhaoらの手法 [10]を参考に、全クライアント間で共有可能な公開データのランダムサブセットを活用した改善手法を採用することとした。具体的には、強震動データフラットファイルの公開観測データを秘匿データしか保有していないクライアントに配布することで、秘匿データを保有するクライアントと公開データを保有するクライアント間のデータ分布を近づけ、学習データごとの偏りを軽減させる。
3.2連合学習の手順
本システムではローカル環境でモデルの学習を行う事業者、モデルパラメータの集約を行う集約者、強震動データフラットファイルの公開観測データを配布するWebサーバの3つのエンティティが登場する。
なお、連合学習におけるモデル集約アルゴリズムの実装にはオープンソースの連合学習用フレームワークであるFlowerフレームワーク [16]を利用した。
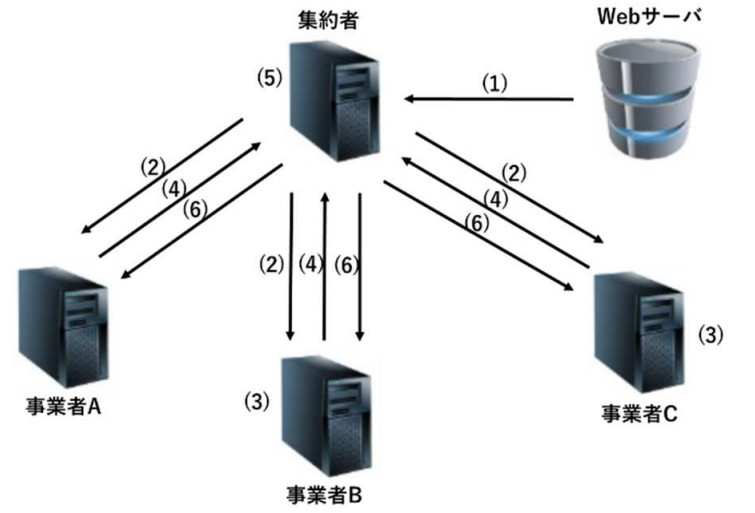
本システム全体のフローは以下の通りである。なお、以下の番号は図1の番号と対応している。
- (1)公開データの取得: 集約者は公開地震観測データを配布するWeb サーバにアクセスし、強震動データフラットファイルの公開観測データを取得する。
- (2)初期化モデルの配布: 集約者が距離減衰式の初期パラメータを設定し、各事業者に配布する。このとき、公開観測データも併せて配布する。
- (3)ローカルモデルの学習: 各事業者は、自身が持つ独自観測データと、強震動データフラットファイルの公開観測データを用いて、受け取ったパラメータを学習・更新する。ローカルでの学習フローの詳細については次節で説明する。
- (4)ローカルモデルの送信: 各事業者は、学習後のローカルモデルのモデルパラメータを集約者へ送信する。
- (5)グローバルモデルの集約: 集約者は各事業者から受け取ったモデルパラメータを集約し、最終的なモデルパラメータとする。集約アルゴリズムにはFedAvgを用いる。
- (6)グローバルモデルの再配布: 集約者は更新されたグローバルモデルを各事業者に再配布する。
3.3ローカルでの学習フロー
各クライアントはそれぞれの学習データセットを用いて以下の手順によって回帰分析を行う。
- (1)司・翠川の距離減衰式を基に、震度を出力する関数を定義する。関数はマグニチュードMw、深さD、断層最短距離Xを説明変数とし、震度yを目的変数とする。また、以下の6つのパラメータθ=(a、h、d、e、c、b)を持つ。関数内部では、式(6)による平均S波速度600[m/s]の工学基盤上における最大速度PGVb600および2.2節で示した式(2)~式(5)による震度yの計算を行う。
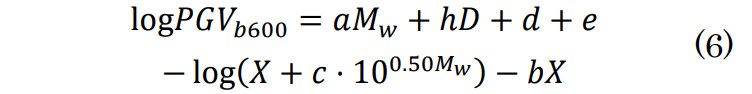
- (2)観測震度と予測震度の誤差を計算する誤差関数Lを定義し、この誤差関数を最小化する最適化問題を解く。誤差の評価指標は二乗平均平方根誤差(RMSE)を採用した。誤差関数は式(7)で定義される。
ここで、ŷiは予測震度、yiは観測震度、Nはデータの総数である。また、誤差関数の最小化には、Adam [17]を使用した。
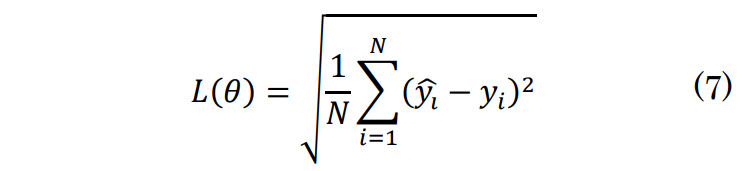
4.実験
4.1実験設定
本システムは事業者が独自に観測した秘匿データと強震動データフラットファイルの公開観測データを併用することを前提としているが、非IIDの秘匿データに対する学習効果の検証のため、データ分布に偏りを持たせた模擬データを用いて実験を行う。本実験では、強震動データフラットファイルの公開観測データの一部を一定のアルゴリズムに基づいてサンプリングしたものを模擬的な秘匿データとした。なお、本実験で使用した観測データは、地震波のエネルギー減衰による観測精度低下を考慮し、回帰分析の品質を確保するため、断層最短距離が300km未満のものに限定している。また、本実験では強震動データフラットファイルが提供する観測点 [18]・震源データ [19] [20] [21] [22] [23]を使用している。
本実験では、3つのクライアントが参加する連合学習の設定を3 通り用意し、それぞれ設定A、設定B、設定Cとした。すべての設定において2つのクライアントが秘匿データを持ち、1つのクライアントが公開データを持つ設定である。これは実際の運用環境を想定し、秘匿データを持つクライアントと公開データを持つクライアントの関係を模擬している。実際には学習に参加するクライアントはさらに多い可能性があるが、クライアント数を増やすと分析要因が複雑化するため、今回は基本的な設定で効果を検証した。なお、すべての実験を通して距離減衰式の初期パラメータは司・翠川 [7]で決定されたパラメータとした。
4.1.1説明変数の分布に偏りがある場合(設定A)
設定Aは、クライアントA1、A2、A3の3者による連合学習である。A1とA2は秘匿データを持つクライアント、A3は公開データを持つクライアントの設定である。
本設定では、秘匿データにおける説明変数の分布に偏りがある環境を想定した。A1は断層最短距離が大きい海域の地震のみを集めたデータ数299のデータセットである。A2はマグニチュードが小さい地震のみを集めたデータ数229のデータセットである。A3は公開データをランダムサンプリングして作成したデータ数5,000のデータセットである。公開データの分配を行う場合、学習の開始段階でA1およびA2に対し、A3が持つ5,000個の公開データから、それぞれ1,000個の公開データが配布される。つまり、公開データをA1およびA2に分配した場合、A3が保持するデータ数は3,000となる。
4.1.2クライアントが保有するデータが多峰的な場合(設定B)
設定Bは、クライアントB1、B2、B3の3者による連合学習である。B1とB2は秘匿データを持つクライアント、B3は公開データを持つクライアントの設定である。
本設定では、特定の地震に対するデータを集めることで、秘匿データのデータ分布が多峰的な分布となるようにサンプリングした。B1は2011年東北地方太平洋沖地震の本震と余震を集めたデータ数200のデータセットである。B2は2016年熊本地震の本震と余震を集めたデータ数200のデータセットである。B3は公開データをランダムサンプリングして作成したデータ数5,000のデータセットである。公開データの分配を行う場合、設定Aの場合と同様に学習の開始段階でB1およびB2に対し、B3が持つ5,000個の公開データから、それぞれ1,000個の公開データが配布される。
4.1.3クライアントごとにデータ数の偏りがある場合(設定C)
設定Cは、クライアントC1、C2、C3の3者による連合学習である。C1とC2は秘匿データを持つクライアント、C3は公開データを持つクライアントの設定である。
本設定では、各クライアントが持つ秘匿データ数が極端に少ない場合を想定した。C1は長野県の観測点NGN001の観測のみからなるデータ数69のデータセットで、震源距離が同程度の地震が多く分布している。C2は京都府の観測点KYT001の観測のみからなるデータ数17のデータセットで、断層最短距離が増加すると最大速度が増加するという傾向を持っている。C3はランダムサンプリングで作成したデータ数5,000のデータセットである。公開データの分配を行う場合、設定A、Bの場合と同様の配布を行う。
4.2評価方法
本実験では、以下の3つのシナリオについて得られたパラメータおよび訓練誤差を評価する。
- ①3者のクライアントが持つデータセットを中央サーバにすべて集約して学習する場合(以下、中央集約)
- ②公開データを分配せずに連合学習を行う場合(以下、FL分配なし)
- ③公開データを分配して連合学習を行う場合(以下、FL分配あり)
なお、ここでは中央集約型学習で得られるモデルと連合学習で得られるモデルのモデルパラメータが一致することが理想である。特に、距離減衰式において地域による特性が反映されやすいパラメータであるa、b、cの値が、中央集約型学習で得られたパラメータにどれだけ近づいているかを評価の観点の一つとする。また、(設定上の)秘匿データに対する訓練誤差も評価観点とする。
4.3実験結果
4.3.1設定A
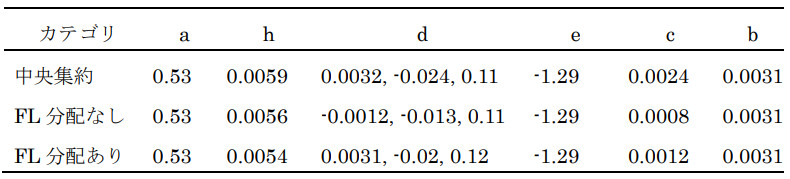
表1に設定Aにおける3つのシナリオそれぞれの実験で得られた最適パラメータを示す。公開データ分配ありのシナリオでは、分配なしのシナリオと比べてパラメータbおよびcの値が中央集約の学習結果に近い結果となった。また、データセットA1およびA2を用いた訓練誤差(RMSE)を比較したところ、中央集約では0.739、FL分配なしでは0.785、FL分配ありでは0.755となり、公開データを分配した場合に訓練誤差が低くなることが確認された。データセットA3に対する訓練誤差は、中央集約型では0.672、FL分配なしでは0.688、FL分配ありでは0.672となった。
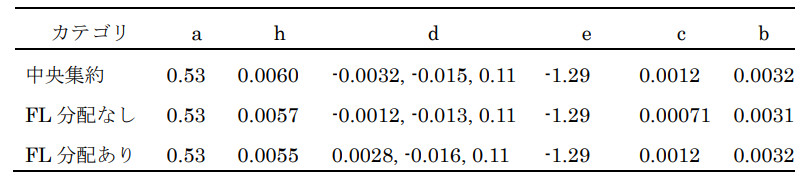
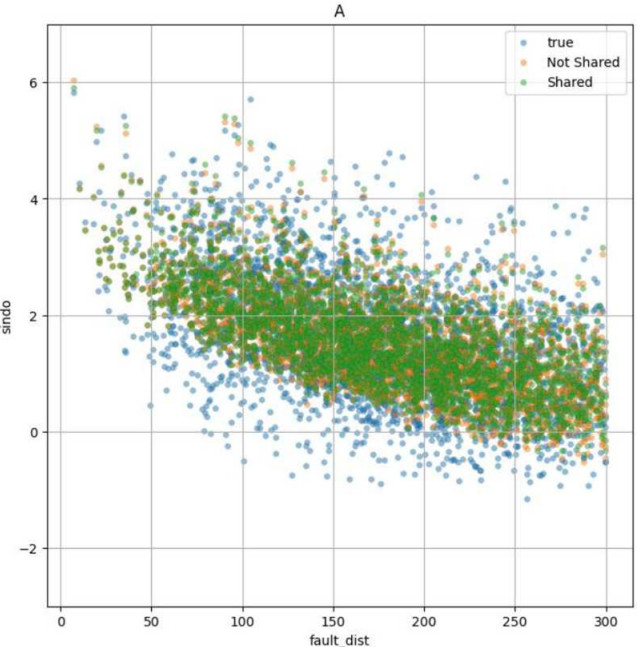
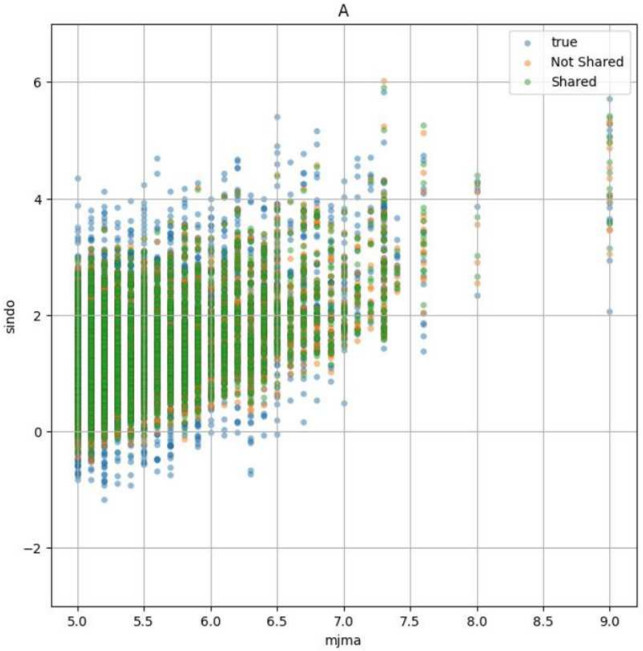
図2、図3はFL分配なし、FL分配ありのそれぞれの最適パラメータに対応するモデルに対してA3のデータを入力として得られた予測震度の分布と、A3のデータに対応する実際の観測震度の分布を示したものである。説明変数のうち、断層最短距離を横軸としたものが図2、マグニチュードを横軸としたものが図3となっている。図の凡例において、FL分配なしシナリオをNot Shared、FL分配ありシナリオをShared、観測震度をtrueと表記している。これらの図から、距離に応じた震度の減衰や、マグニチュードの増加に伴って震度が大きくなる関係が正しく学習されていることが確認できる。
4.3.2設定B
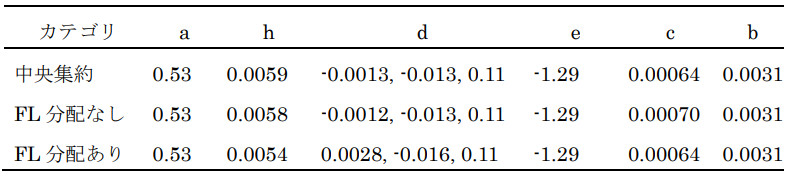
表2に設定Bにおける3つのシナリオそれぞれの実験で得られた最適パラメータを示す。公開データ分配ありのシナリオでは、分配なしのシナリオと比べて、パラメータcの値が中央集約の学習結果に近い結果となった。また、データセットB1およびB2を用いた誤差(RMSE)を比較したところ、中央集約では0.641、FL分配なしでは0.652、FL分配ありでは0.647となり、公開データを分配した場合に訓練誤差が低くなることが確認された。データセットB3に対する訓練誤差は、中央集約では0.674、FL分配なしでは0.672、FL分配ありでは0.671となった。
4.3.3設定C
表3に設定Cにおける3つのシナリオそれぞれの実験で得られた最適パラメータを示す。公開データ分配ありのシナリオでは、分配なしのシナリオと比べて、パラメータcの値が中央集約の学習結果に近い結果となった。また、データセットC1およびC2 を用いた誤差 [3](RMSE)を比較したところ、中央集約では0.690、FL分配なしでは0.687、FL分配ありでは0.689となり、すべての場合でほぼ差はなかった。データセットC3に対する訓練誤差は、中央集約では0.674、FL分配なしでは0.672、FL分配ありでは0.671となった。
5.考察
5.1学習性能
実験結果から、公開データの分配によって中央集約型学習で得られるモデルと連合学習で得られるモデルの間の差異を小さくできることが確認できた。設定AおよびBでは、公開データを分配することでパラメータb、cの値が中央集約型学習の結果に近づき、訓練誤差(RMSE)も低下した。一方設定Cでは、公開データの分配による改善効果は限定的であり、訓練誤差の変化もわずかであった。これは設定Cのクライアントが持つデータ数が少なく、またデータ数に対する配布数の割合もA、Bと比べ非常に大きいことから、クライアントが持つデータの分布が公開データとほとんど同じ分布になってしまい、分布の偏りによる影響が現れなかったと考えられる。総じて、公開データの分配は特にデータの偏りが顕著な場合に、連合学習の学習性能を安定化させるために有効な手法であることが示唆された。
5.2今後の課題
今回の実験では、クライアント間のデータの偏りが極端になるよう意図的にサンプリングを行っているが、実際の運用環境ではこのような顕著な差が生じない可能性がある。今後の課題として、事業者が現に保有しているデータを用いることで、実際に発生しうるデータの偏りに合わせた評価を行うことが挙げられる。また、本システムでは分配する公開データのサイズを固定しているが、適切な分配データサイズを定量的に決定するための指標を確立することも今後の重要な課題である。加えて、本研究では集約アルゴリズムとしてFedAvgを用いたが、非IIDデータによる影響を抑制するFedProx [24]、SCAFFOLD [25] 等他の集約アルゴリズムを用いた場合との比較も行い、より適切な手法を選定する必要がある。
6.むすび
本研究では、独自の地震観測網を持つ複数の事業者が連合学習を用いて協調することで、プライバシーを確保した上で各事業者のデータを活用可能な地震動予測モデルの構築を行った。予測モデルは司・翠川の距離減衰式を対象とし、連合学習で各パラメータの再学習を行った。さらに、非IIDデータの影響を軽減するため、学習に参加する全クライアント間で共有可能な公開データのランダムサブセットを活用し、非IIDデータ環境におけるグローバルモデル性能低下の防止を図った。その結果、中央集約型学習で得られるモデルと、連合学習で得られるモデルとの差異を小さくできることを確認した。今後の課題として、データの分配サイズを定量的に決定するための指標の確立や、FedAvg以外の集約アルゴリズムによる結果との比較、差分プライバシー等の手法の適用によるデータ秘匿性およびセキュリティ向上が挙げられる。
参考文献
- [1]気象庁, “緊急地震速報のしくみ,” [オンライン]. Available: https://www.jma.go.jp/jma/kishou/know/jishin/eew/shikumi/shikumi.html .
- [2]防災科学技術研究所, “地震ハザードステーションJ-SHIS,” [オンライン]. Available: https://www.j-shis.bosai.go.jp/ .
- [3]地震調査研究推進本部, “距離減衰式,” [オンライン]. Available: https://www.jishin.go.jp/resource/terms/tm_attenuation_relation/ .
- [4]Koneˇcn`y, J, “Federated Learning: Strategies for Improving Communication Efficiency,” arXiv preprint arXiv:1610.05492, 2016.
- [5]Shamir, A., “How to share a secret,” Communications of the ACM, Vol. 22, No. 11, pp. 612-613, 1979.
- [6]Gentry, C., “A fully homomorphic encryption scheme,” Stanford university, 2009.
- [7]司宏俊,翠川三郎, “断層タイプ及び地盤条件を考慮した最大加速度・最大速度の距離減衰式,” 日本建築学会構造系論文集, Vol. 64, No. 523, pp. 63-70, 1999.
- [8]森川信之,岩城麻子,藤原広行,秋山伸一,前田宜浩,久保久彦,青井真,早川俊彦,高橋真理,加藤研一,佐藤俊明,林孝幸,岡崎智久,司宏俊,松山尚典,翠川三郎, “K-NET・KiK-net 強震動記録のフラットファイル構築,” 日本地震工学シンポジウム論文集, Day3-G403-20, 2023.
- [9]Moshawrab, M., Adda, M., Bouzouane, A., Ibrahim, H. and Raad, A., “Reviewing federated learning aggregation algorithms; strategies, contributions, limitations and future perspectives,” Electronics, Vol. 12, No. 10, p. 2287, 2023.
- [10]Zhao, Y., Li, M., Lai, L., Suda, N., Civin, D. and Chandra, V., “Federated learning with non-iid data,” arXiv preprint arXiv:1806.00582, 2018.
- [11]Vepakomma, P., Gupta, O., Swedish, T. and Raskar, R., “Split learning for health: Distributed deep learning without sharing raw patient data,” arXiv preprint arXiv:1812.00564, 2018.
- [12]McMahan, B., Moore, E., Ramage, D., Hampson, S. and y Arcas, B. A., “Communication-efficient learning of deep networks from decentralized data, Artificial intelligence and statistics,” PMLR, pp. 1273-1282, 2017.
- [13]Morikawa, N., and H. Fujiwara, “A new ground motion prediction equation for Japan applicable up to M9 mega-earthquake,” Journal of Disaster Research, Vol. 8, pp. 878-888, 2013.
- [14]松岡昌志,翠川三郎, “国土数値情報とサイスミックマイクロゾーニング,” 第22 回地盤震動シンポジウム資料集, 23M34, 1994.
- [15]防災科学技術研究所, “強震動データフラットファイル,” https://doi.org/10.17598/NIED.0032, 2025.
- [16]Beutel, D. J., Topal, T., Mathur, A., Qiu, X., Fernandez- Marques, J., Gao, Y., Sani, L., Li, K. H., Parcollet, T., de Gusm~ao, P. P. B. et al., “Flower: A friendly federated learning research framework,” arXiv preprint arXiv:2007.14390, 2020.
- [17]Kingma, D. P., “Adam: A method for stochastic optimization.,” arXiv preprint arXiv:1412.6980, 2014.
- [18]防災科学技術研究所, “強震観測網(K-NET, KiK-net),” [オンライン]. Available: https://www.kyoshin.bosai.go.jp/kyoshin/ .
- [19]気象庁, “地震月報(カタログ編),” [オンライン]. Available: https://www.data.jma.go.jp/eqev/data/bulletin/index.html .
- [20]防災科学技術研究所, “気象庁一元化処理震源リスト,” [オンライン]. Available: https://hinetwww11.bosai.go.jp/auth/JMA/jmalist.php?LANG=ja .
- [21]防災科学技術研究所, “F-net メカニズム解カタログ,” [オンライン]. Available: https://www.fnet.bosai.go.jp/event/search.php?LANG=ja .
- [22]EQUAKE-RC, “SRCMOD断層モデルデータベース,” [オンライン]. Available: http://equake-rc.info/srcmod/ .
- [23]地震調査研究推進本部, “毎月の地震活動,” [オンライン]. Available: https://www.jishin.go.jp/evaluation/seismicity_monthly/ .
- [24]Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A. and Smith, V., “Federated optimization in heterogeneous networks,” Proceedings of Machine learning and systems, Vol. 2, pp. 429-450, 2020.
- [25]Karimireddy S.P., Kale S., Mohri M., Reddi S., Stich S., Suresh A.T., “SCAFFOLD: Stochastic Controlled Averaging for Federated Learning,” PMLR 119:5132-5143, 2020.