2022年度 三菱電機ソフトウエア技術レポート
マルチコアDSP上でのアプリケーション開発
1. まえがき
近年のDSP(注1)においてもCPUと同様に処理性能向上のためマルチコア化が行われている。今回の開発において、ソフトウェアのブートやDMA(注2)、シリアルバス等のDSP内蔵周辺機器のドライバ、コア間通信ドライバ、デバッグツール等を製作し、複数ソフトウェア間での共通化を実現した。本技報では、その開発内容を報告するとともに、DSPソフトウェアの処理時間の高速化手順についても報告する。
- (注1)Digital Signal Processorの略で、デジタル信号処理に特化したプロセッサ。
- (注2)Direct Memory Access Controllerの略で、メモリ間等のデータ転送を自動化する周辺機器。
2. 開発の概要
マルチコアDSPを、電波応用システムの処理性能向上のため、信号処理ソフトウェアのプラットフォームに採用した。それを搭載するDSP基板、FPGA、ソフトウェアを三菱電機株式会社が開発し、その開発に当社も参画した。
ソフトウェア開発では、複数の異なるアプリケーションを並列に製作する必要があり、効率化のため、アプリケーション間で共通利用可能なドライバ等の製作を行った。
2.1 DSP
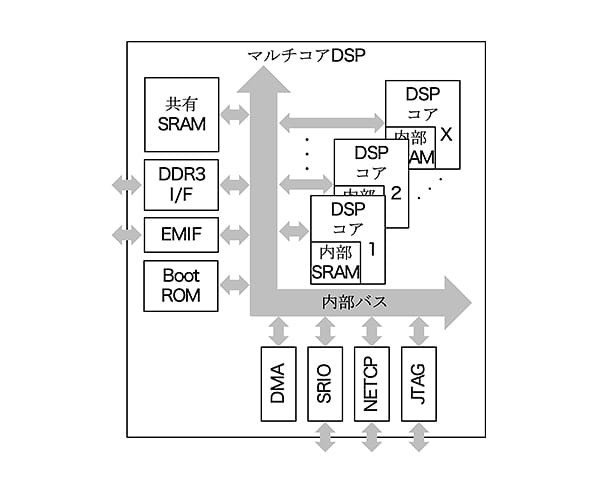
図 1. 選定したDSPの概略構成
搭載するマルチコアDSPは、当社が過去に開発実績のあるDSPの後継機種であり、かつ開発の効率化が望める浮動小数点演算をサポートするTexas Instruments社製DSPを選定した。
選定したDSPは図 1に示すように、複数のDSPコア、コアごとの内部SRAM、コア間共有メモリに使用可能な共有SRAM、DDR3メモリのインタフェース、EMIF(注3)、DMA、SRIO(注4)、NETCP(注5)、JTAG®(注6)等のDSP内蔵周辺機器から構成される。
- (注3)External Memory Interfaceの略で、外部機器とバス接続するためのインタフェース。
- (注4)Serial RapidIOの略で、FPGAやDSPとのデータ転送に使用する標準規格の高速シリアルバス。
- (注5)Network Coprocessorの略で、イーサネット・パケットを処理するハードウェア・アクセラレータ、外部のイーサネット物理層デバイスと接続するSGMII(Serial Gigabit Media Independent Interface)等から構成し、LAN通信を実現する周辺機器。
- (注6)IEEE 1149.1として標準化され、ソフトウェアデバッグ等に使用するインタフェース。
2.2 DSP基板
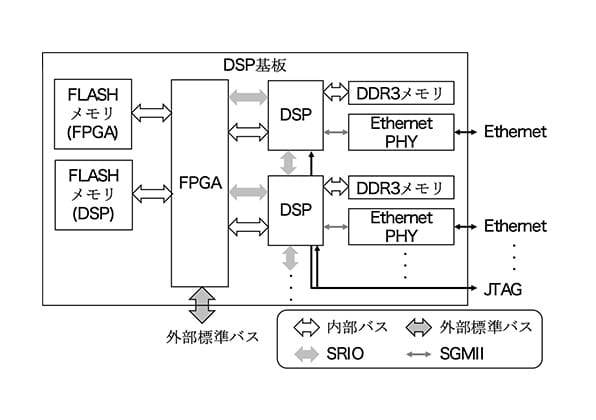
図 2. DSP基板の概略構成
開発したDSP基板は図 2に示すように、複数のマルチコアDSP、DDR3メモリ、FPGA、Ethernet® PHY、FPGAのコンフィグレーションデータ格納用Flashメモリ、DSPプログラム格納用Flashメモリ等で構成した。
DSPとFPGA間のSRIO接続はFPGAからの処理データの入力に、EMIFバス接続はFPGAに搭載するレジスタへのアクセスに、DSP間のSRIO接続はDSP間の処理データの入出力に使用した。また、各DSPとEthernet® PHYを接続し、処理結果の外部出力に使用した。
2.3 開発環境
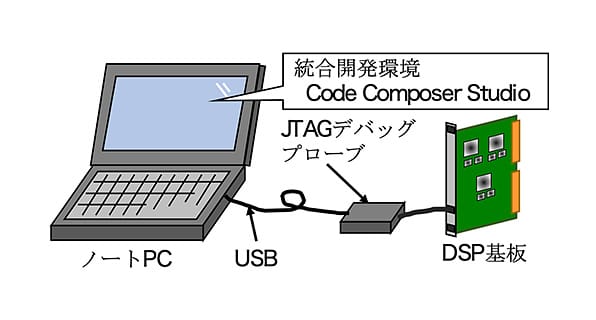
図 3. 開発環境の構成
開発環境は図 3に示すように、統合開発環境にCode Composer Studio®を使用し、DSP基板とJTAG®デバッグプローブを接続した。
3. 開発内容
本章では、採用したOS、開発した電源投入時のブート、DSP内蔵周辺機器のドライバ、DSP内通信、DSP間通信について記す。また、処理の高速化手順、デバッグ環境についても記す。
3.1 採用OS
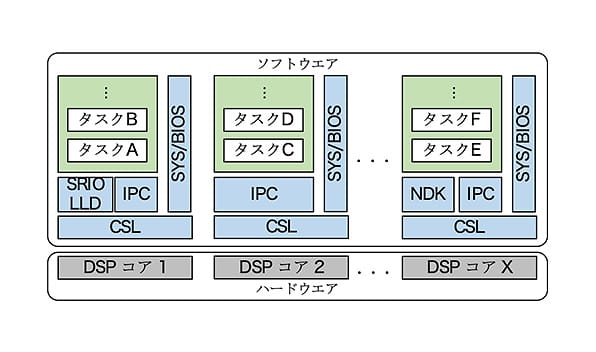
図 4. ソフトウェア構成
過去の開発実績からリアルタイムOSであるSYS/BIOSを採用した。また、DSP内蔵周辺機器へのレジスタアクセスライブラリにCSL(注7)、SRIOの制御ドライバにSRIO LLD(注8)、LAN通信のためのプロトコルスタックにNDK(注9)、コア間通信にIPC(注10)を採用した。これらOSやライブラリのソフトウェア構成を図 4に示す。
採用したOSはコアごとに独立した実体として動作し、アプリケーションに応じてコアごとに異なるタスクを動作させる必要がある。このため、コアごとにプログラムを製作することが基本になる。しかし、複数のプログラムを製作する必要があり、開発が非効率になることが想定された。そのため、DSPのメモリ空間に着目し、次に示すワーク用メモリの配置、タスク動作を工夫することにより、1つのプログラムで全コア分のOS、タスクを実行可能とした。
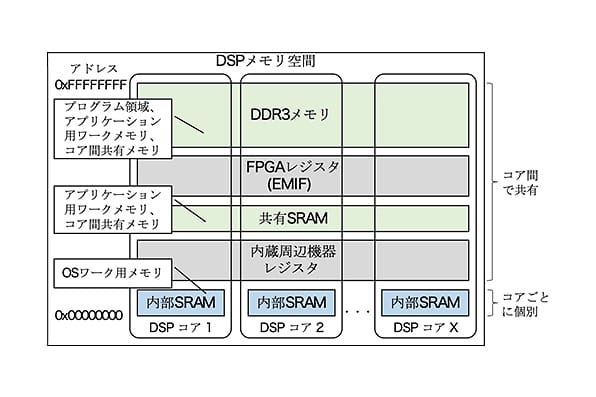
図 5. DSPメモリ空間と主な用途
DSPメモリ空間は図 5に示すように、コアごとに個別に有する内部SRAMとコア間で共有となる共有SRAM、DDR3メモリがある。このうち、内部SRAMにOSのワーク用メモリを配置した。これにより、1つのプログラムで、OS をコアごとに独立した実体として動作するようにした。また、タスクはプログラムに含まれる全コア分のタスク中からコアごとの切替え動作とした。
- (注7)Chip Support Libraryの略で、DSP内蔵周辺機器のレジスタ操作関数群で構成するソフトウェアライブラリ。
- (注8)Low Level Driverの略で、DSP内蔵周辺機器の低水準なドライバソフトウェア。
- (注9)Network Developer's Kitの略で、NETCPのドライバ、通信プロトコルスタックから構成するソフトウェアライブラリ。
- (注10)Inter-Processor Communicationの略で、コア間のメッセージング、共有メモリ制御等から構成するするソフトウェアライブラリ。
3.2 ブート
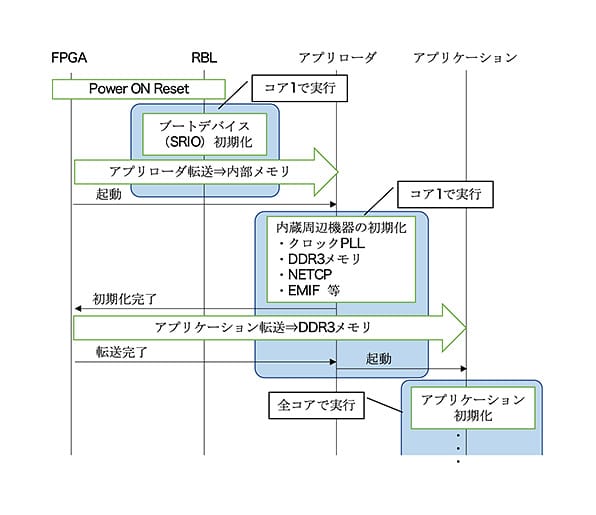
図 6. ブート手順
DSP基板に電源が投入されると、DSP組込みのRBL(注11)がコア1で起動し、DSPの接続端子で指定された転送に使用するDSP内蔵周辺機器を初期化し、プログラムコードをコア1の内部SRAMに転送する。転送に使用するDSP内蔵周辺機器として、SRIO、NETCP等から選択可能であるが、FPGAとの接続があるSRIOを選択した。図 5に示すとおりアプリケーションのプログラムコードは、DDR3メモリに配置する必要があり、RBLのみではアプリケーションをロードできない。そのため、RBLは、アプリケーションをロードするプログラム(以降、アプリローダと呼称)をロードし、アプリローダがアプリケーションをロードする仕組みとした。
DSP基板に電源が投入されてからアプリケーションが起動するまでの手順を図 6に示す。DSP基板に電源が投入されると、DSP組込みのRBLが起動する。RBLによりアプリローダがロードされると、アプリケーションのロード先であるDDR3メモリ等のDSP内蔵周辺機器を初期化、FPGAにアプリケーションの転送を要求する。FPGAがSRIO経由でアプリケーションを転送し、転送完了後、全コアでアプリケーションを起動する。
- (注11)ROM Bootloaderの略で、ブートに使用するDSP内蔵周辺機器の初期化、プログラムコードの内部SRAMへの転送を行うDSP組込みのソフトウェア。
3.3 DSP内蔵周辺機器ドライバ
DSP内蔵周辺機器を使用する際に使うCSL、LLDは汎用的に作成されており、アプリケーションに適用する際にDSP内蔵周辺機器に関する多くの知識が必要になる。複数のアプリケーション開発者が容易にDSP内蔵周辺機器を使用可能とするために、使用する機能に限定し、過去に開発した他のDSPのドライバと同じインタフェースになるようCSL、LLDをラップするドライバを製作した。これにより、共通的に利用できるようになった。
また、DSP内蔵周辺機器はコア間の共有資源であり競合を回避するため、そのドライバは特定のコアでのみ動作するようにした。
3.4 DSP内通信
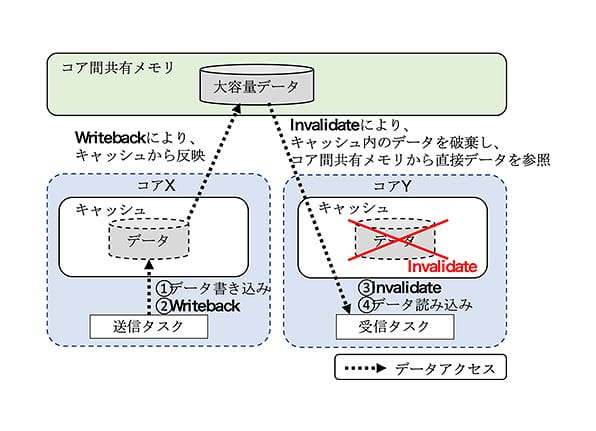
図 7. コア間共有メモリを使用した大容量データ通信
マルチコアDSPのソフトウェアは図 4に示すように、複数のタスクがコアごとに独立して稼働するOS上で動作する。
DSP内の通信には同一コア内のタスク間通信、異なるコア間のコア間通信がある。タスク間通信は、SYS/BIOSが提供するMailbox機能(注12)を活用し、コア間通信は、IPCが提供するMessageQ機能(注13)を活用した。
各通信は、共通の関数インタフェースで実現し、それぞれの通信を区別する必要がない仕組みとした。これにより、処理時間制限等で、タスクを動作させるコアを変更する必要が発生した際、容易に変更可能とした。
また、大容量データの送受をするコア間通信を、コア間でメモリサイズが大きいDDR3メモリを共有することにより実現した。大容量データの送受は、図 7に示す手順で行う。コアごとに異なるキャッシュを有し、キャッシュを操作することにより、データの一貫性を保つ必要がある。そのため、データを送信するタスクは、データ書き込み後、キャッシュのWriteback(注14)を実施し、受信するタスクはデータを読み込み前にキャッシュのInvalidate(注15)をする。各タスクがキャッシュを操作することで、共有メモリ上のデータを更新又は参照することができ、コア間でデータの一貫性を保つことができる。
- (注12)コア内部のメモリを使用し、同一コア内のタスク間でメッセージ通信を可能とする機能。
- (注13)コア間共有メモリを使用し、異なるコア間でメッセージ通信を可能とする機能。
- (注14)キャッシュからコア間共有メモリへデータを書き込む(Writeback)操作。
- (注15)キャッシュのデータを破棄することにより、無効(Invalidate)とする操作。
3.5 DSP間通信
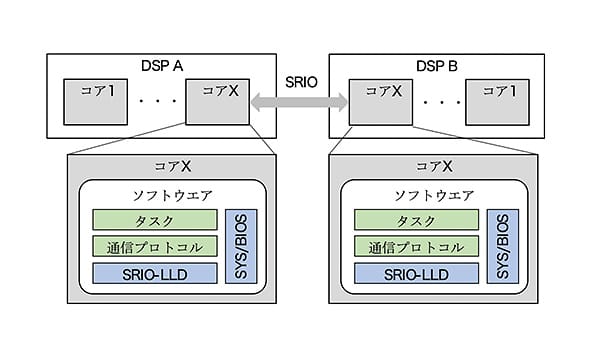
図 8. DSP間通信のソフトウェア構成
DSP間通信のソフトウェア構成を図 8に示す。DSP間を接続するSRIOを使用し、そのドライバであるSRIO LLD上に通信プロトコルを実装し、500Mbps以上の伝送速度を実現した。
3.6 アプリケーションの処理高速化
DSP上でソフトウェアの処理時間を計測した結果、要求される処理時間に収まらない関数があった。そこで、要求性能を満たすために、その関数の高速化を行った。
3.6.1 処理時間の計測方法
コア内部にTSC(注16)が内蔵されており、動作クロックの逆数の分解能で時間を計測できる。計測区間の両端でTSCのカウンタ値を取得し、その差分から処理時間を計測した。
- (注16)Time Stamp Counterの略で、CPUの動作クロックでカウントする64bitカウンタ。
3.6.2 使用メモリの変更
図 5に示したとおり、DSPのメモリ空間にはアプリケーションから使用可能なワークメモリが複数存在し、変数ごとに配置するメモリをソースコード上で指定できる。
ワークメモリの転送時間の測定結果を表 1に示す。ここで、表 1の転送時間は、最大値を1として規格化した。DDR3メモリと比べ、内部SRAM、共有SRAMの転送速度が高速であり、内部SRAMと共有SRAMは同等の速度であった。
- (注16)Time Stamp Counterの略で、CPUの動作クロックでカウントする64bitカウンタ。
| No | メモリ | 転送サイズ(byte) | |||
|---|---|---|---|---|---|
| 512 | 1,024 | 2,048 | 4,096 | ||
| 1 | DDR3メモリ | 0.25 | 0.37 | 0.59 | 1.00 |
| 2 | 共有SRAM | 0.06 | 0.11 | 0.20 | 0.38 |
| 3 | 内部SRAM | 0.07 | 0.12 | 0.23 | 0.46 |
表 1. ワークメモリへの転送時間 測定結果
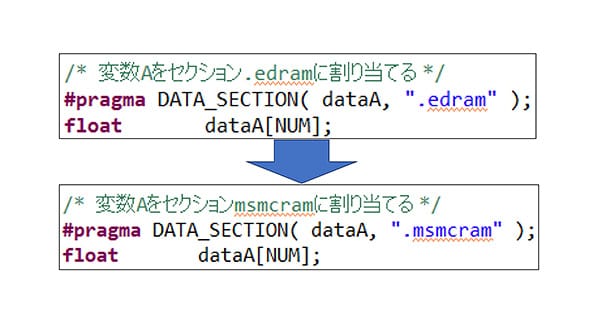
図 9. 使用メモリの変更
高速化前、関数が頻繫にアクセスする変数をDDR3メモリに配置していたが、より高速な共有SRAMに配置することで、処理の高速化を図った。
変数のメモリ配置をDDR3メモリから共有SRAMに変更する場合、 図 9に示すように、コンパイラの#pragma宣言を使用する。ここで、DDR3メモリ及び共有SRAMのセクション名を”.edram”、”.msmcram”とあらかじめ命名した。
3.6.3 for文の削減・簡略化
for文内の処理は繰り返し実行され、処理高速化による改善効果が大きい。そこで、以下の3つの観点でソースコードを見直した。
- ①統合可能なfor文は、統合する。
- ②for文内の変数等を統合し、処理を単純化する。
- ③for文外で実行可能な処理は、外に移動する。
②の見直しの例として、見直し前の処理を図 10、見直し後の処理を図 11に示す。
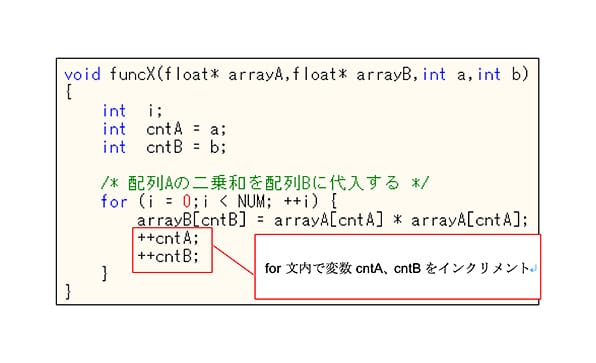
図 10. for文内の変数統合(見直し前)

図 11. for文内の変数統合(見直し後)
3.6.4 最適化アドバイスの適用
DSPは複数命令を並列実行することにより高速化できる。この機能を活用するためにはコンパイラが並列実行可能な命令を出力するソースコードとする必要がある。
コンパイラのアドバイザリ機能を有効にすることで、コンパイラが出力するアセンブリファイルに処理高速化のための最適化アドバイスを挿入できる。そのアドバイスに従い、ソースコードを見直した。主なアドバイスの和訳を表 2に、アドバイスが挿入されたアセンブリファイルを図 12に示す。”Performance”と書かれた箇所が、最適化アドバイスである。また、行先頭の二重線(||)は並列実行する命令であることを表し、最適化されたことを表す。
| No | 最適化アドバイス |
|---|---|
| 1 | ループ内に関数呼び出しがあるので、効果的にスケジューリングできません。 |
| 2 | ポインタ変数1、2が同じメモリ領域にアクセスしない場合、restrict修飾子を追加してください。 |
| 3 | このループが常にNの倍数、少なくともN回実行されることがわかっている場合は、「#pragma MUST_ITERATE(N, ,N)」を追加してください。 |
表 2. 最適化アドバイス例(和訳)
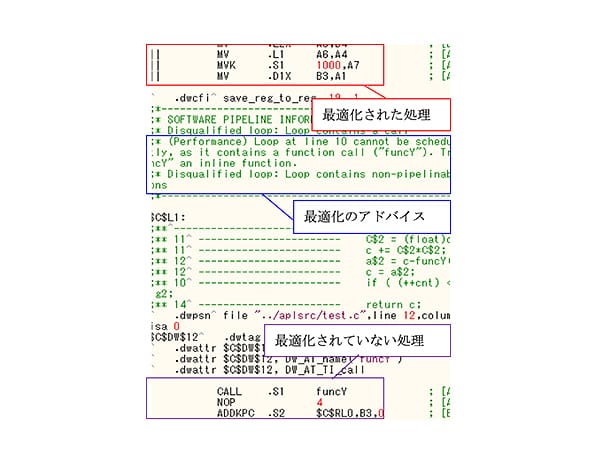
図 12. アセンブリファイル
3.6.5 処理高速化の結果
| No | 最適化アドバイス | 処理時間 |
|---|---|---|
| 1 | -(改善前) | 5.03 |
| 2 | 使用メモリの変更 for文の削減・簡略化 |
2.05 |
| 3 | 番号2の内容に加え、更なる使用メモリの変更最適化アドバイスの適用 | 1.92 |
| 4 | 番号3の内容に加え、更なるfor文の削減・簡略化 更なる最適化アドバイスの適用 |
0.49 |
表 3. 処理高速化の結果
処理高速化の結果を表 3に示す。処理時間は複数回測定の最悪値を採用し、要求性能を1とした比で表した。表 3に示すとおり、3.6.2~3.6.4項に示す修正を試行錯誤し、処理時間の要求性能を満たすことができた。
3.7 デバッグ
3.7.1 Telnetによるデバッグ
デバッグにJTAG®デバッグプローブを使用する場合、メモリ状態の確認にはDSPの動作を停止する必要があり、実時間での状態確認が不可能である。また、JTAG®デバッグプローブが接続不可能な遠隔地では使用できない。そこで、開発したソフトウェアにTelnetサーバを組み込み、Telnet接続経由でデバッグ用コマンドの実行を可能にした。これにより、実時間での状態確認及び遠隔地でのデバッグを可能にした。Telnetを用いたデバッグ環境を図 13に、主要なデバッグ用コマンドを表 4に示す。
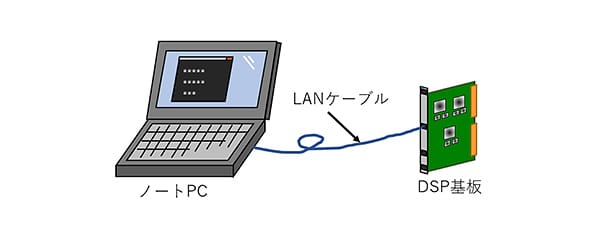
図 13. Telnet接続経由のデバッグ環境
| No | 最適化アドバイス |
|---|---|
| 1 | バージョンを表示する |
| 2 | 指定アドレスのメモリ内容を表示する |
| 3 | 指定アドレスのメモリ内容を変更する |
| 4 | 障害発生履歴を表示する |
表 4. 主要なデバッグ用コマンド
3.7.2 外部からの障害発生履歴の確認
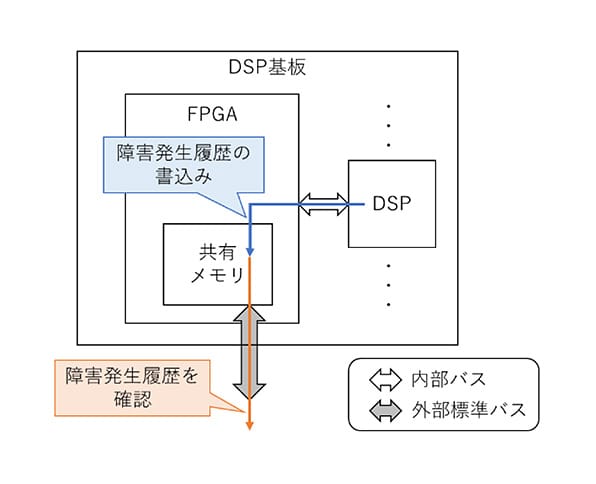
図 14. 外部からの障害発生履歴の確認
ハングアップ等でDSPが制御不能になると、JTAG®デバッグプローブやTelnetでの状態確認ができない。そこで、ソフトウェアが出力する障害発生履歴を、外部標準バスからアクセス可能な共有メモリに記録することで、外部のCPUなどから確認可能にした。外部からの障害発生履歴の確認イメージを図 14に示す。
4. むすび
今回の開発にてドライバ、デバッグツールの共通化ができたとともに、DSP内蔵周辺機器の制御、処理高速化等のマルチコアDSP上でのアプリケーション開発のノウハウの蓄積ができた。
今後は、製作するアプリケーションへのドライバ、デバッグツールの適用を継続するとともに、将来採用が見込まれる新規プロセッサへの適用を検討することにより、適用範囲の拡大に取り組む予定である。
| 【謝辞】 |
マルチコアDSP上のアプリケーション開発にあたり、ご指導を賜った三菱電機株式会社 通信機製作所 EWシステム部 システム第一課、システム第四課、ソフトウエア技術部 ソフトウエア技術第一課、技術部 デジタル技術第二課の皆様に深く感謝する。 |
|---|---|
| 【商標】 |
Code Composer Studioは、テキサスインスツルメンツインコーポレーテツド社の登録商標である。 |